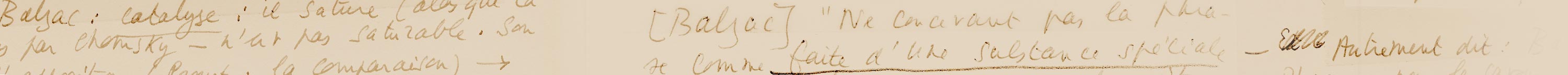| Auteur | Titre | Date |
| CHARDIN PHILIPPE | L’AUTORITÉ PERDUE PUIS RETROUVÉE DE LA SCIENCE CHEZ FLAUBERT, CHEZ MUSIL ET CHEZ PROUST | 2016-07-04 |
| Perrier Guillaume | La mémoire du critique : Georges Poulet et Marcel Proust | 2016-06-27 |
| Morizono Vivian Yoshie Martins | Marcel Proust et João do Rio, chroniqueurs de salons | 2016-02-01 |
| Anjos Yuri Cerqueira dos | Mobilité proustienne, Mobilité journalistique. | 2016-02-01 |
| Martin Jordy | Ambiguïté générique des prépublications du Figaro : chronique journalistique et art poétique | 2016-02-01 |
| Siri Nicole | Le « tournant homosexuel » de Saint-Loup : vers une déconstruction du discours du narrateur autour de la sexualité | 2016-02-01 |
| Dolléans Géraldine | Un « effet Walter Scott » d’À la recherche du temps perdu ?
Proust et l’École des Annales | 2016-02-01 |
| McGuinness Max | Presse et modernité dans l’œuvre de Proust | 2016-02-01 |
| Güngören Didem Nur | L’éveil du corps sensible : le corps comme fondation de la conscience dans À la recherche du temps perdu | 2016-02-01 |
| Fadabini Sara | Proust et la parole vide | 2016-02-01 |
| Cerfon Audrey | L’oreille hallucinée | 2016-01-20 |
| Güngören Didem Nur | L’éveil du corps sensible : le corps comme fondation de la conscience dans À la recherche du temps perdu | 2015-12-22 |
| Ferrer Daniel | An Unwritten Chapter of Ulysses?
Joyce’s Notes for a “Lacedemon” Episode | 2015-09-11 |
| Willemart Philippe | Où est l'incertitude dans la quête du souvenir chez le narrateur proustien ? | 2015-09-08 |
| Willemart Philippe | Où est l'incertitude dans la quête du souvenir chez le narrateur proustien ? | 2015-09-08 |
| Bem Jeanne | « On va ailleurs, c’est encore pire » : les enjeux de l’incipit de la iie partie de Madame Bovary | 2015-07-15 |
| Coorebyter Vincent de | Le manuscrit « Liberté – Égalité » | 2014-06-26 |
| CHARDIN PHILIPPE | La dialectique proustienne des rapports maître/serviteur d’après le personnage de Françoise dans Du côté de chez Swann “Combray” | 2013-09-12 |
| Doubrovsky Serge | Les points sur les « i » | 2013-06-27 |
| Grell Isabelle | Première approche d’un avant-texte de Laissé pour conte de Serge Doubrovsky | 2013-06-27 |
| Anokhina Olga | ESTUDIOS SOBRE MULTILINGÜISMO Y CREACIÓN:
Eje prioritario de la política europea. | 2013-06-19 |
| Louis Marie-Victoire | Abécédaire
Libres définitions / [choix de] citations / interprétations / digressions / réflexions [féministes]... | 2013-06-18 |
| Herschberg Pierrot Anne | Les manuscrits de Roland Barthes par Roland Barthes, style et genèse | 2013-03-01 |
| Pierrot Anne Herschberg | Notes sur la mort de la grand-mère. | 2013-02-06 |
| Archives des actualités proustiennes /2011-2012 | 2013-02-05 |
| Fenoglio Irène | "Benveniste auteur d’une recherche inachevée sur « le discours poétique » et non d’un « Baudelaire »" | 2013-02-05 |
| Sicard Monique | Monique Sicard s’entretient avec Jean-Marie Fadier | 2012-12-11 |
| Paone Domenico, Petruzzelli* Francesco | Deux volumes de manuscrits d’Ernest Renan retrouvés dsdsd | 2012-11-29 |
| Archives des actualités proustiennes 2011-2012 | 2012-11-26 |
| Paone Domenico, Petruzzelli Francesco | Deux volumes de manuscrits d’Ernest Renan retrouvés | 2012-10-30 |
| Constantin Danielle | Sur les traces du « scrivain » : les manuscrits de La Vie mode d’emploi | 2012-09-18 |
| Leblay Christophe | En deçà du bien et du mal écrire. | 2012-06-14 |
| Leblay Christophe | L’avant-texte comme texte sur le vif. | 2012-06-05 |
| Leblay Christophe | L’avant-texte: le moi en émoi. | 2012-06-05 |
| Courtine-Denamy Sylvie | Entre Deux Langues. Langue et affect | 2012-06-04 |
| Courtine-Denamy Sylvie | “Une seule langue, un seul peuple ” ? De la Genèse à Ben Gourion. | 2012-06-04 |
| Courtine-Denamy Sylvie | Pour les Juifs, le Mot est la seule patrie. | 2012-06-04 |
| CNRS-ITEM Louis Hay | L’édition critique et la génétique dans la longue durée. | 2012-02-03 |
| Brun Bernard | Les cent cahiers de Marcel Proust : Comment a-t-il rédigé son roman ? | 2011-12-13 |
| André Julie | « Couchage » et « gougnotage » :
les jeux de l’amour dans les cahiers de brouillon de Proust | 2011-12-13 |
| Maspero Janeta, HONTEBEYRIE Micheline | Paul Valéry
Les brouillons de La Jeune Parque : constatations et interrogations | 2011-11-19 |
| Sicard Monique | D’où viennent les lumières de l‘œuvre ? /From where are the artistic work’s lights coming ? | 2011-09-19 |
| Crasson Aurèle, Sicard Monique | - Séminaire « Photo-graphies : théories, pratiques, images/ Genèses photographiques » /2010-2011 | 2011-09-18 |
| Sicard Monique | Duchenne de Boulogne, médecin-photographe (1806 – 1875) | 2011-09-08 |
| Passos Marie-Hélène Paret | Crítica genética, tradução literária e performatividade: quando escrever é fazer | 2011-09-07 |
| PARRET PASSOS Marie-Hélène | Critique génétique et traduction littéraire :
Eric Nepomuceno traduit Gabriel Garcia Marquez | 2011-09-07 |
| Sicard Monique | Entretien avec Georges Rousse | 2011-09-05 |
| Montini Chiara | La traduction du Procès de Kafka par Primo Levi : un conflit entre le même et l’autre | 2011-08-31 |
| Montini Chiara | La réception de Beckett en Italie | 2011-07-27 |
| Montini Chiara | La traduction comme exorcisme du corps dans l’écriture bilingue de Samuel Beckett | 2011-07-27 |
| Montini Chiara | Monolinguisme, pluringuisme ou "mixtilinguisme"? L'Italie et l'Irlande entre langues nationales et littérature. | 2011-07-26 |
| Montini Chiara | Le rôle du bilinguisme de Beckett dans la genèse de Mercier and Camier | 2011-07-26 |
| Montini Chiara | Avant et après Babel, l’intraduisible dans l’œuvre de Primo Levi. | 2011-07-25 |
| Wise Pyra | Sur une note de régie elliptique de Proust : les Saint-Marceaux et les nymphéas de Monet | 2011-06-27 |
| Willemart Philippe | Le parlé coulé dans l’écrit :recherche de la sonorité dans l’écriture proustienne | 2011-06-23 |
| Almeida Alexandre Bebiano de | La « chambre maritime » de Proust : à propos du Cahier 38 | 2011-06-22 |
| André Julie | « Couchage » et « gougnotage » :
les jeux de l’amour dans les cahiers de brouillon de Proust | 2011-06-20 |
| Cavalcanti Carla | La composition proustienne et la reconstitution des brouillons : l’exemple du Cahier 52 | 2011-06-17 |
| Silva Guilherme Ignácio da | Esprit et raillerie chez les Guermantes : retour sur le contexte d’une création | 2011-06-17 |
| Teyssandier Laurence | Les additions du Cahier 49 : des liens génétiques entre la « race des tantes » et « M. de Charlus pendant la guerre »? | 2011-06-17 |
| Murad Samira | Quelques remarques sur le Cahier 15 : lectures et lecteurs | 2011-05-26 |
| Herschberg Pierrot Anne | Où en est la génétique flaubertienne ? | 2011-02-28 |
| Wise Pyra | Une source négligée de la boutade de Gautier sur Racine : Maxime Gaucher, un professeur de Marcel Proust au Lycée Condorcet1 | 2011-01-06 |
| Duval Sophie | Le verre grossissant et l’art du tailleur d’images :
un point de détail autoréférentiel au revers du texte proustien | 2011-01-06 |
| Fenoglio Irène | Conceptualisation linguistique : du manuscrit au texte.
Contribution à l’étude des spécificités de l’écriture scientifique | 2010-10-11 |
| Fenoglio Irène | Évènements graphiques, genèse et énonciation.
La question du détail et de l’imprevisible | 2010-10-11 |
| SEGALA MARCO | Ampère filosofo | 2010-09-02 |
| De Cian Nicoletta, SEGALA MARCO | What is will?* | 2010-09-02 |
| SEGALA MARCO | Schopenhauer è antischellinghiano? | 2010-08-04 |
| SEGALA MARCO | Autobiografia e Storiografia | 2010-08-04 |
| SEGALA MARCO | Avogadro e la classificazione delle scienze | 2010-08-04 |
| SEGALA MARCO | Beethoven, Hoffmann e la musica assoluta | 2010-08-04 |
| SEGALA MARCO | Électricité animale, magnétisme animal, galvanisme universel: à la recherche de l'identité entre l’homme et la nature | 2010-08-04 |
| SEGALA MARCO | Goethe, Schopenhauer e l’ottica sperimentale | 2010-08-04 |
| SEGALA MARCO | An Italian in Bavaria: Campetti, Ritter and the destiny of science in Germany | 2010-08-04 |
| Jacquet Claude | Joyce et Rabelais
Aspects de la création verbale dans Finnegans Wake | 2010-05-06 |
| CHARDIN PHILIPPE | Processes of Rebirth from Short Story to Novel | 2009-10-27 |
| Ackerman Ada | A lire sur le site caricaturesetcaritature.com | 2009-10-26 |
| Fenoglio Irène | Les notes de travail d'Emile Benveniste | 2009-09-29 |
| Bigot Eric-Olivier Le | Le site web des Cahiers de Paul Valéry | 2009-06-23 |
| Fenoglio Irène | Du texte avant le texte.
Formes génétiques et marques énonciatives de pré-visions textualisantes | 2009-06-23 |
| CHARDIN PHILIPPE | « Réminiscences anticipées " et " Ramiers fraternels » : Les réécritures de quelques romans européens du XIXè siècle dans Le Temps retrouvé de Marcel Proust | 2009-06-05 |
| Ferrer Daniel | Towards a Marginalist Economy of Textual Genesis | 2009-06-04 |
| Hay Louis | Images du Manuscrit 1 | 2009-06-02 |
| Herschberg Pierrot Anne | Cette brume de la mémoire | 2009-03-23 |
| Grésillon Almuth, Lebrave Jean-Louis | Linguistique et génétique des textes : un décalogue | 2009-03-23 |
| Willemart Philippe | L'immersion dans l'écriture : les incipit de Salammbô | 2009-03-23 |
| Herschberg Pierrot Anne | Notes sur le style des marges dans la Vie de Henry Brulard | 2009-03-18 |
| Fenoglio Irène | La fin de Tre Cavalli1 | 2009-03-11 |
| Willemart Philippe | De l'Histoire de Zobéide à La Recherche : de la dérive des formes aux processus de création | 2009-03-09 |
| Willemart Philippe | De la forme aux processus de création dans La Recherche | 2009-03-09 |
| Fenoglio Irène | Fête des Chants du Marais, un conte inédit de Pascal Quignard1. | 2009-03-09 |
| Fenoglio Irène | « Je ne suis pas un écrivain, je suis un rédacteur de variantes » | 2009-03-09 |
| Calil Eduardo, Felipeto Cristina | Quand la rature (se) trompe : une analyse de l’activité métalinguistique | 2009-02-17 |
| Calil Eduardo | Processus de création et ratures : analyse d’un processus d’écriture dans un texte rédigé par deux écolières | 2009-02-16 |
| Lebrave Jean-Louis, Grésillon Almuth | Linguistique et génétique des textes : un décalogue | 2009-02-16 |
| WADA Mitsumasa | L’Episode de la chimie dans Bouvard et Pécuchet de Flaubert, ou comment narrativiser une ambiguïté scientifique | 2009-01-16 |
| Ferrer Daniel | Quelques remarques sur le couple intertextualité-genèse | 2009-01-15 |
| Hay Louis | Qu’est-ce que la critique génétique?1 | 2008-12-09 |
| Hay Louis | Genèse de la génétique | 2008-11-30 |
| CHARDIN PHILIPPE | Proust et ses "surmoi" classique et flaubertien | 2008-10-14 |
| Herschberg Pierrot Anne | Clichés, Stéréotypie et stratégie discursive dans le discours de Lieuvain (« Madame Bovary », II, 8) | 2008-09-22 |
| Boltz Déborah | Réception de L’Éducation sentimentale. Troisième partie (1985-1995) | 2008-09-14 |
| Boltz Déborah | Réception de L’Éducation sentimentale. Deuxième partie (1975-1985) | 2008-09-14 |
| Boltz Déborah | Réception de L’Éducation sentimentale. Introduction générale | 2008-09-14 |
| Boltz Déborah | Réception de L’Éducation sentimentale. Première partie (1880-1975) | 2008-09-14 |
| Boltz Déborah | Réception de L’Éducation sentimentale. Quatrième partie (1995-2005) | 2008-09-14 |
| Boltz Déborah | Réception de L’Éducation sentimentale. Bilan critique général | 2008-09-14 |
| Boltz Déborah | Réception de L’Éducation sentimentale. Bibliographie génétique | 2008-09-14 |
| Pierrot Anne Herschberg | Flaubert journaliste : Présentation | 2008-09-09 |
| Sicard Monique | Les origines du dispositif cinématographique : une hypothèse multifactorielle | 2008-08-19 |
| PAGES Alain | Émile Zola : genèse du roman familial | 2008-08-18 |
| Riffard Claire | Ecrire en deux langues. | 2008-07-07 |
| Sicard Monique | François Arago (1786 – 1853) et le régime photographique | 2008-07-03 |
| Lörinszky Ildikó, Péter Ádám | Le chapeau escamoté | 2008-07-03 |
| Chamchinov Sergueï | Les dessins et les manuscrits de Michaux | 2008-07-03 |
| Sicard Monique | Photographie : Quel récit des origines ? | 2008-07-02 |
| Lörinszky Ildikó | Le désert flaubertien | 2008-07-02 |
| Ildiko Lörinszky | Flaubert képtára (trad. fr. "La Galerie de Flaubert") | 2008-07-02 |
| Wise Pyra | Pour la bibliothèque de Marcel Proust | 2008-05-26 |
| Mauriac Dyer Nathalie | Note sur M. de Lomperolles dans Jean Santeuil, ou un aspect négligé de la genèse de Charlus | 2008-05-26 |
| Mauriac Dyer Nathalie | Proust Procuste : les fins disjointes d’À la recherche du temps perdu | 2008-05-26 |
| Henrot Geneviève | D’un bleu de cinéraire. Note sur un fragment de la Recherche1 | 2008-05-22 |
| Henrot Geneviève | Mnémosyne et le bruissement de la langue. Version française de « Mnemosyne and the Rustle of Language : Proustian Memory Reconsidered » | 2008-05-21 |
| Sostero Geneviève Henrot | Les Surprises de la mémoire ou la Boîte de Pandore | 2008-05-20 |
| Henrot Geneviève | Le Mille e una memoria di Marcel Proust | 2008-05-16 |
| Henrot Sostero Geneviève | Un concerto dé-concerté. Histoire conversationnelle du baron de Charlus | 2008-05-15 |
| Henrot Geneviève | L’Architexture du signe proustien | 2008-05-07 |
| Henrot Geneviève | À propos d’« impressions ». Petite mise au point | 2008-05-06 |
| Genette Raymonde Debray | Comment faire une fin | 2008-05-06 |
| Bérenger Caroline | Les carnets de notes dans l’œuvre de Tsvétaeva | 2008-04-26 |
| Bérenger Caroline | Записные книжки в творчестве Марины Цветаевой | 2008-04-26 |
| Garros Véronique | Terreur et « intimité » | 2008-04-26 |
| Мари-Элеонора Шартье | « Дневник » Марии Башкирцевой как объект цензуры | 2008-04-19 |
| Lejeune Philippe | Une petite causette : Benda, Léautaud | 2008-04-19 |
| Montémont Véronique, Simonet-Tenant Françoise | Douleur exquise : un monstre générique tragico-ludique | 2008-04-19 |
| К. Вьолле , Е.П. Гречаная | Дневник в России в конце XVIII - первой половине XIX в. как автобиографическая практика | 2008-04-19 |
| Филипп Лежен | « Я » Марии | 2008-04-19 |
| Lejeune Philippe | Introduction à la table ronde « Cinéma, autobiographie et genèse » | 2008-04-19 |
| Simonet-Tenant Françoise | Trois journaux russes féminins | 2008-04-19 |
| Artières Philippe, Cugnon Gilles | La Pudeur ou l’impudeur d’Hervé Guibert | 2008-03-17 |
| Bustarret Claire, Linkès Serge | Un nouvel instrument de travail pour l’analyse des manuscrits : la base de données MUSE | 2008-03-16 |
| Артьер Филипп, Даббади Дени | Автобиография как борьба: генезис второй части « Запечатленного труда » Веры Фигнер | 2008-03-13 |
| Вьолле Катрин | Параллельное письмо : Французские путевые дневники молодых русских аристократок (1841-1847) | 2008-03-13 |
| Лежен Филипп | Когда кончается литература ? | 2008-03-13 |
| Bustarret Claire | Paper Evidence and the Interpretation of the Creative Process in Modern Literary Manuscripts | 2008-03-09 |
| Constantin Danielle | La rédaction de La Vie mode d’emploi de Georges Perec : la pièce de la mémoire | 2008-02-28 |
| Bosse Anke | « Perles poétiques » issues d’un « matériau prodigieux » | 2008-02-26 |
| Hulle Dirk Van | Économie textuelle : recyclage chez Proust, Mann et Joyce | 2008-02-26 |
| Barsht Konstantin, Bérenger Caroline | Dostoïevski : le dessin comme écriture | 2008-02-25 |
| Men Ségolène Le | L’œuvre d’art en devenir
Chemins faisant…et « prés parés » | 2008-02-21 |
| Jakobi Marianne | Nommer la forme et l’informe | 2008-02-19 |
| Zimmermann Tania, F. Zimmermann Michael | La spirale, forme de pensée de la création | 2008-02-19 |
| van de Sandt Audrey, Zimmermann Tania, F. Zimmermann Michael | La spirale, forme de pensée de la création | 2008-02-19 |
| Gamboni Dario | Fiction et vérité | 2008-02-19 |
| Lungo Andrea Del | Plaisirs du titre et souffrances du commencement | 2008-02-15 |
| Riffard Claire | Francophonie littéraire : quelques réflexions autour des discours critiques | 2008-02-05 |
| Genette Raymonde Debray | Les débauches apographiques de Flaubert | 2008-01-25 |
| Ferrer Daniel | Combien d’enfants avait Lady Gervaise ? Le style de l’invention dans les ébauches de Zola | 2007-12-29 |
| Debray Genette Raymonde | Génétique et théories littéraires | 2007-12-15 |
| Guermès Sophie | Zola, l’Église et la morale sexuelle | 2007-12-10 |
| Pellegrini Florence | Espace mode d’emploi : l’esthétique tabulaire chez Flaubert et Perec | 2007-12-10 |
| Milesi Laurent | Supplementing Babel: Paget in VI.B.32 | 2007-12-07 |
| Goujon Francine | Morel ou la dernière incarnation de Lucien | 2007-12-06 |
| Lumbroso Olivier | De la palette à l’écritoire1 | 2007-12-06 |
| Lumbroso Olivier | Médan ou la maison de papier | 2007-12-06 |
| Lumbroso Olivier | Passage des Panoramas | 2007-12-05 |
| Goujon Francine | « Je » narratif, « Je » critique et écriture intertextuelle dans le Contre-Sainte-Beuve | 2007-12-05 |
| Goujon Francine | Références balzaciennes et cryptage autobiographique dans Du côté de chez Swann | 2007-12-05 |
| Lumbroso Olivier | Topologie d’un champ de bataille | 2007-12-04 |
| Guermès Sophie | L’aménagement du territoire | 2007-12-03 |
| Guermès Sophie | Génétique et poétique du drame passionnel dans Rome : vers un élargissement du naturalisme ? | 2007-12-03 |
| Milesi Laurent | La variante Joycienne et Perecquienne : Études contrastives | 2007-11-26 |
| Milesi Laurent | Poétiques de genèses Joyciennes | 2007-11-26 |
| Herschberg Pierrot Anne | Prose et épopée | 2007-11-26 |
| Vachon Stéphane | Construire dit-il | 2007-11-21 |
| PAGES Alain | J’accuse... Un cri pour la rue | 2007-11-20 |
| PAGES Alain | Le Discours argumentatif de J’accuse | 2007-11-20 |
| Vachon Stéphane | La gestion balzacienne du classement : du “catalogue Delloye” aux Notes sur le classement et l'achèvement des œuvres | 2007-11-16 |
| Vachon Stéphane | La Même histoire d'une femme de trente ans : “J'ai corrigé l'édition qui sert de manuscrit” | 2007-11-16 |
| Herschberg Pierrot Anne | De Bouvard et Pécuchet aux Enfants du limon | 2007-11-15 |
| PAGES Alain | La rhétorique de J’accuse | 2007-11-15 |
| Biasi Pierre-Marc de | Le cauchemar de Marcel Proust | 2007-11-07 |
| Genette Raymonde Debray | Génétique et poétique : le cas Flaubert | 2007-10-29 |
| Pellegrini Florence | “Mais pourquoi m’a-t-elle fait ça !” : Bouvard, Pécuchet et la recherche des causes. Une approche génétique et linguistique des connecteurs de causalité dans Bouvard et Pécuchet de Gustave Flaubert | 2007-10-26 |
| Lebrave Jean-Louis | Lecture et analyse des brouillons | 2007-10-26 |
| Lebrave Jean-Louis | L’écriture inachevée | 2007-10-26 |
| Lebrave Jean-Louis | Les manuscrits entre la substance de l’expression et la substance du contenu | 2007-10-25 |
| Le Calvez Éric | L’horreur en expansion. Génétique de la « grillade des moutards » dans Salammbô | 2007-09-17 |
| Aquien Michèle, Pickering Robert | Les cahiers 1894-1914 de Paul Valéry en édition intégrale Historique, enjeux, avenir | 2007-09-08 |
| Dufour Philippe | Propos de table | 2007-09-07 |
| PAGES Alain | Émile Zola : Bilan critique | 2007-09-06 |
| PAGES Alain | Émile Zola : Bilan critique | 2007-09-06 |
| Viollet Catherine | Petite cosmogonie des écrits autobiographiques | 2007-09-01 |
| Cugnon Gilles, Artières Philippe | Sida-Mémoires | 2007-09-01 |
| Simonet-Tenant Françoise | Catherine Pozzi : le Journal comme laboratoire de l'oeuvre | 2007-09-01 |
| Dufour Philippe | Le lecteur introuvable | 2007-07-12 |
| Fekete Jean-Daniel, Crasson Aurèle | Structuration des manuscrits : Du corpus à la région | 2007-07-11 |
| Lebrave Jean-Louis, Grésillon Almuth | « Quand tous mes autres moi seront morts... » Réflexions sur l'hologramme proustien | 2007-07-11 |
| Grésillon Almuth, Viollet Catherine | « Quand tous mes autres moi seront morts... » Réflexions sur l'hologramme proustien | 2007-07-11 |
| Viollet Catherine, Lebrave Jean-Louis | « Quand tous mes autres moi seront morts... » Réflexions sur l'hologramme proustien | 2007-07-11 |
| Neefs Jacques | La prévision de l'oeuvre | 2007-07-10 |
| Viollet Catherine | Mutations génétiques d’un récit : « Un pas vers Gomorrhe » d’Ingeborg Bachmann | 2007-07-05 |
| Allain-Castrillo Monique | Préposé(e) à… ou la dimensioninternationale des Cahiers de Paul Valéry | 2007-07-05 |
| Ganascia Jean-Gabriel, Fenoglio Irène | Manuscrits, genèse et documents numérisés. EDITE : une étude informatisée du travail de l’écrivain | 2007-07-05 |
| Ganascia Jean-Gabriel, Fenoglio Irène | Manuscrits, genèse et documents numérisés. EDITE : une étude informatisée du travail de l’écrivain | 2007-07-05 |
| Viollet Catherine | « La Confession d'une jeune fille » : aveu ou fiction ? | 2007-07-04 |
| Ganascia Jean-Gabriel, Fenoglio Irène | EDITE MEDITE : un logiciel de comparaison de versions | 2007-07-03 |
| Ganascia Jean-Gabriel, Fenoglio Irène | EDITE MEDITE : un logiciel de comparaison de versions | 2007-07-03 |
| Doquet-Lacoste Claire | Trajets d’écriture, trajets de mots : | 2007-07-02 |
| Neefs Jacques | L'énonciation graphique (l’écriture des manuscrits) | 2007-06-28 |
| Neefs Jacques | Les trois étages du mimétique dans La Comédie humaine | 2007-06-28 |
| Lemonnier-Delpy Marie-Françoise | La mémoire du texte1 | 2007-06-26 |
| Doquet-Lacoste Claire | Ecriture et traitement de texte à l’école élémentaire : | 2007-06-25 |
| Doquet-Lacoste Claire | Le jeune scripteur et ses doubles. | 2007-06-25 |
| GIFFORD Paul | « Ce poème (que je n’ai pas pu faire) » : l’herméneutique d’une émergence, 1910-1913 | 2007-06-15 |
| Coorebyter Vincent de | Le développement philosophique du Carnet Dupuis | 2007-06-14 |
| Coorebyter Vincent de | Présentation des esquisses inédites pour la Critique de la Raison dialectique | 2007-06-14 |
| Mitterand Henri | Intertexte et avant-texte : la bibliothèque génétique des Rougon-Macquart | 2007-06-14 |
| VOGEL Christina | Les Cahiers de Valéry entre ordre et désordre | 2007-06-14 |
| Coorebyter Vincent de | Structure et genèse de la Légende de la vérité | 2007-06-14 |
| Pickering Robert | La réception critique des Cahiers 1894-1914 de Paul Valéry (Éditions Gallimard) | 2007-06-13 |
| Anokhina Olga | Compte rendu. Michel Fayol (dir.), Production du langage. Traité des sciences cognitives, Paris, Hermès/Lavoisier, 2002, 314 p. | 2007-06-13 |
| Neefs Jacques | La projection du scénario | 2007-06-13 |
| HONTEBEYRIE Micheline | Les Cahiers de Paul Valery, ferments de genèse poétique | 2007-06-13 |
| Celeyrette-Pietri Nicole | L’édition intégrale des Cahiers | 2007-06-13 |
| Willemart Philippe | De quel inconscient parlons-nous dans le manuscrit ? | 2007-06-13 |
| Neefs Jacques | L’illusion du sujet | 2007-06-12 |
| Neefs Jacques | Flaubert et la mimesis scénarique | 2007-06-11 |
| Contat Michel | Autopsie d'un livre inexistant : La Reine Albemarle ou le Dernier touriste1 | 2007-06-11 |
| Wise Pyra | Proust et Nietzsche | 2007-05-25 |
| CHARDIN PHILIPPE | Rupture interminable et travail de deuil dans la littérature européenne du début du siècle : Proust, Kafka, Svevo | 2007-05-23 |
| Mauriac Dyer Nathalie | Genèse de la « Ruine de Venise » | 2007-05-14 |
| Anokhina Olga | Du brouillon au texte imprimé : genèse d’une œuvre poétique | 2007-04-04 |
| Hay Louis | Les manuscrits au laboratoire | 2007-04-03 |
| Herschberg Pierrot Anne | Étude génétique de l’incipit de Bouvard et Pécuchet | 2007-04-02 |
| Hay Louis | Qu’est-ce que la génétique ? | 2007-04-02 |
| Hay Louis | Ecrire hors des pages | 2007-04-02 |
| Pétillon Sabine | De l’intermittence pronominale : sur la polyphonie énonciative dans le manuscrit et l’état définitif du Plaisir du texte de Roland Barthes | 2007-04-02 |
| Pétillon Sabine | Intentionnalité et révision à l’épreuve du manuscrit d’écrivain. Genèse de Génitrix de Mauriac | 2007-03-29 |
| Herschberg Pierrot Anne | Les notes de Proust | 2007-03-28 |
| Mauriac Dyer Nathalie | Deux notes à propos du texte de « La Prisonnière » | 2007-03-28 |
| Brun Bernard | À la recherche du Contre Sainte-Beuve | 2007-03-20 |
| Fenoglio Irène | L’intime étrangeté de la langue | 2007-03-19 |
| Lebrave Jean-Louis | La genèse de La Chambre claire | 2007-03-19 |
| Duval Sophie | « Une répétition destinée à suggérer une vérité neuve » : Itération et régénération comique chez Proust | 2007-03-16 |
| Wise Pyra | Trois lettres et une dédicace inédites de Marcel Proust conservées à la Pierpont Morgan Library | 2007-03-16 |
| Hamon Philippe | L’image dans la fabrique : avant‑textes | 2007-03-15 |
| Brun Bernard | De quelques plaisanteries antisémites dans les manuscrits de rédaction du roman | 2007-03-15 |
| Mauriac Dyer Nathalie | « Le temps, le temps, le temps pur… » Claude Mauriac, du Journal au Temps immobile | 2007-03-15 |
| Duval Sophie | Mundus inversus et terra incognita : inversion, homosexualité et ironie dans Sodome et Gomorrhe | 2007-03-14 |
| Duval Sophie | Ironie, humour et « réminiscences anticipées » : la construction des dames de Cambremer et l’histoire de l'art selon Proust | 2007-03-14 |
| Mauriac Dyer Nathalie | Défense de Flaubert (1919-1922) | 2007-03-14 |
| Brun Bernard | Le Fauteuil magique | 2007-03-14 |
| Mauriac Dyer Nathalie | Mille feuilles de l’écriture : les cahiers manuscrits « au net » de Marcel Proust et la question éditoriale | 2007-03-13 |
| Wise Pyra | Deux lettres de Marcel Proust à Robert de Montesquiou retrouvées dans des bibliothèques américaines | 2007-03-13 |
| Wise Pyra | Les lettres de Marcel Proust dans le Fonds Henry Bordeaux à Chambéry : retour sur une amitié et présentation de trois lettres dont deux inédites | 2007-03-13 |
| Mitterand Henri | Le méta‑texte génétique dans les Ébauches de Zola | 2007-03-11 |
| Leriche Françoise, Mauriac Dyer Nathalie | Les Proust aux « Lieux » : Du Traité d’hygiène à Sodome et Gomorrhe | 2007-03-09 |
| Duval Sophie | Un involontaire homme d’esprit : naïveté, théâtralité ironique et trope méta-communicationnel chez Proust | 2007-03-09 |
| Mauriac Dyer Nathalie | Albertine disparue, les Oeuvres libres, et l’oubli | 2007-03-09 |
| CHARDIN PHILIPPE | Comparer pour « écrire de soi » | 2007-03-08 |
| Hamon Philippe | Échos et reflets. L’Ébauche de La Bête humaine de Zola | 2007-03-08 |
| Biasi Pierre-Marc de | Bovary, mythe féminin | 2007-03-07 |
| Biasi Pierre-Marc de | La genèse du projet en situation de concours : entretien avec Édith Girard | 2007-03-07 |
| Biasi Pierre-Marc de | L’énigme des deux origines | 2007-03-07 |
| Biasi Pierre-Marc de | Le patrimoine écrit | 2007-03-07 |
| Teyssandier Laurence | Proposition de M. de Gurcy / Charlus au héros à la sortie de l’hôtel de Guermantes. [Cahiers 7, 24, 49, 43] | 2007-03-07 |
| Mauriac Dyer Nathalie | Proust et l’esthétique de la clôture intermédiaire | 2007-03-06 |
| Mauriac Dyer Nathalie | Poétique de la surprise : Aristote et Proust | 2007-03-06 |
| Grésillon Almuth, Lebrave Jean-Louis | Flaubert: “Ruminer Hérodias" | 2007-03-06 |
| Hay Louis | Lire et écrire | 2007-02-21 |
| Hay Louis | Text oder Genese : der Streit an der Grenze1 | 2007-02-21 |
| Plongées | 2007-02-15 |
| Lejeune Philippe | Vers une grammaire de l’autobiographie | 2007-02-15 |
| Vogel Ruth | Montauk de Max Frisch, réécritures et autocensure | 2007-02-15 |
| Montémont Véronique | Lorand Gaspar : genèse des Carnets de Patmos | 2007-02-15 |
| Simonet-Tenant Françoise | J. H. Lartigue. L’autofiction d’un homme heureux | 2007-02-15 |
| Becker Colette | Du meurtrier par hérédité au héros révolutionnaire. Étienne Lantier dans le dossier préparatoire de Germinal | 2007-02-15 |
| Lumbroso Olivier | Éléments pour une critique génétique cognitiviste (L’imagerie mentale chez Zola) | 2007-02-11 |
| Lumbroso Olivier | Forme du métatexte et métatexte de la forme | 2007-02-11 |
| Scarpa Marie | Des avant‑textes au roman : l’exemple du Ventre De Paris. Approche génétique et ethnocritique | 2007-02-08 |
| Lumbroso Olivier | Espace et Création : l’invention de l’espace dans la genèse de Germinal d’Émile Zola | 2007-02-07 |
| Scarpa Marie | Les poissons rouges sont‑ils solubles dans le réalisme ?
Lecture ethnocritique d’un « détail » du Ventre de Paris | 2007-02-05 |
| Pierre‑Gnassounou Chantal | Discrétion et indiscrétion de Zola | 2007-02-05 |
| Hay Louis | Génétique et théorie littéraire | 2007-01-29 |
| Hay Louis | Critiques du manuscrit | 2007-01-29 |
| Hay Louis | Autobiographie d’une genèse | 2007-01-29 |
| PAGES Alain | La lysogenèse du texte romanesque | 2007-01-28 |
| Michel Contat | La genèse sociale des Séquestrés d’Altona de Jean‑Paul Sartre | 2007-01-28 |
| Lumbroso Olivier | Quand détruire, c’est créer. Censure et autocensure dans la genèse de L’Assommoir | 2007-01-28 |
| PAGES Alain | Pour une génétique de l’imprimé. L’étape de la prépublication | 2007-01-24 |
| Fonyi Antonia | Du Zola pur et propre. Approche psychanalytique de la genèse de La Faute de l’abbé Mouret et du Rêve | 2007-01-23 |
| PAGES Alain | Comment Zola écrivait‑il ? | 2007-01-23 |
| PAGES Alain | Correspondance et avant‑texte | 2007-01-23 |
| Contat Michel | De « Melancholia » à La Nausée. La normalisation NRF de la Contingence | 2007-01-21 |
| Genèse et censure psychique. L’exemple de Maupassant | 2007-01-21 |
| Ferrer Daniel | Introduction au volume 47 des Finnegans Wake Notebooks at Buffalo | 2007-01-19 |
| Biasi Pierre-Marc de | Qu’est ce qu’un brouillon ? Le cas Flaubert : essai de typologie fonctionnelle des documents de genèse | 2007-01-19 |
| Biasi Pierre-Marc de | What is a Literary Draft? Towards a functional typology of genetic documentation | 2007-01-19 |
| Ferrer Daniel | La toque de Clementis : rétroaction et rémanence dans les processus génétiques | 2007-01-19 |
| Ferrer Daniel | Le matériel et le virtuel : du paradigme indiciaire à la logique de mondes possibles | 2007-01-19 |
| Daniel Ferrer | Peut‑on parler de métalepse génétique ? | 2007-01-19 |
| Ferrer Daniel | Quelques remarques sur le couple énonciation‑genèse | 2007-01-19 |
| Ferrer Daniel | Reflections on a discarded set of proofs | 2007-01-19 |
| Ferrer Daniel | What song the sirens sang... is no longer beyond all conjecture. A preliminary description of the new « Proteus » and « Sirens » manuscripts | 2007-01-19 |
| Fenoglio Irène | Énonciation et genèse dans les autobiographies d’Althusser. Deux récits – séparés – de sa rencontre avec Hélène | 2007-01-19 |
| Bustarret Claire | Découpage, collage et bricolage : la dynamique matérielle du brouillon moderne | 2007-01-19 |
| Ferrer Daniel | The open space of the draft page: James Joyce and Modern Manuscripts | 2007-01-19 |
| Becker Colette | Cela « s’établira en écrivant » (Zola) | 2007-01-19 |
| Montémont Véronique | Anny Duperey, Le Voile noir | 2007-01-19 |
| Pickering Robert, Haffner Françoise | Lieux génétiques inédits chez Paul Valéry
Des feuilles volantes et des Cahiers aux premiers brouillons de La Jeune Parque, 1907‑1913 | 2007-01-19 |
| Pickering Robert, Haffner Françoise | Lieux génétiques inédits chez Paul Valéry
Des feuilles volantes et des Cahiers aux premiers brouillons de La Jeune Parque, 1907‑1913 | 2007-01-19 |
| Biasi Pierre-Marc de | Flaubert : dynamique de la genèse | 2007-01-18 |
| Biasi Pierre-Marc de | Édition horizontale, édition verticale. Pour une typologie des éditions génétiques (le domaine français 1980‑1995) | 2007-01-18 |
| Becker Colette | Sur les sentiers de la création : les dossiers préparatoires des Rougon‑Macquart | 2007-01-18 |
| Biasi Pierre-Marc de | Pour une politique d’enrichissement du patrimoine écrit | 2007-01-18 |
| Biasi Pierre-Marc de | Le papier, fragile support de l’essentiel | 2007-01-18 |
| Biasi Pierre-Marc de | L’avant‑texte | 2007-01-18 |
| Biasi Pierre-Marc de, Legault Réjean | La clarté des archives | 2007-01-18 |
| Biasi Pierre-Marc de | Flaubert : le travail de l’écriture | 2007-01-18 |
| Biasi Pierre-Marc de | Pour une analyse scientifique des manuscrits | 2007-01-18 |
| Becker Colette | Le collage, tremplin pour l’invention : l’utilisation du journal par Zola | 2007-01-18 |
| Grésillon Almuth | La double contrainte:texte et scène dans la genèse théâtrale1 | 2006-11-27 |
| Grésillon Almuth, Lebrave Jean-Louis | Flaubert: Ruminer Hérodias | 2006-11-23 |
| Grésillon Almuth | La critique génétique, aujourd'hui et demain | 2006-11-21 |
| Ferrer Daniel | La critique génétique : « Philosophy of Composition » ou « Gold Bug » ? | 2006-11-09 |
| Lebrave Jean-Louis | La critique génétique : une discipline nouvelle ou un avatar moderne de la philologie? | 2006-11-09 |
| Grésillon Almuth | Le langage de l'ébauche: parole intérieure extériorisée | 2006-11-07 |
| Lebrave Jean-Louis | L’édition critique au XXIe siècle | 2006-10-31 |
| Grésillon Almuth | Raturer, rater, rayer, éradiquer, radier, irradier | 2006-10-23 |
| Brun Bernard | Marcel Proust et la religion | 2006-10-19 |
| Fenoglio Irène | Écriture en acte et genèse de l’énonciation | 2006-10-17 |
| Lebrave Jean-Louis | Hypertextes — Mémoires — Ecriture | 2006-10-16 |
| Viollet Catherine | Une petite machine à re-monter le temps | 2006-09-26 |
| Viollet Catherine | Violette Leduc, de Ravages à La Bâtarde1 | 2006-09-26 |
| Fenoglio Irène | Les événements d’énonciation graphique. | 2006-09-25 |
| Fenoglio Irène | l’autonymie dans les rectifications de lapsus | 2006-09-21 |
| Fenoglio Irène | Une photo, deux textes, trois manuscrits. l’archivage linguistique d’un geste d’écriture identifiant | 2006-09-21 |
| Fenoglio Irène | L’hic et nunc de l’écrire immémorial | 2006-09-21 |