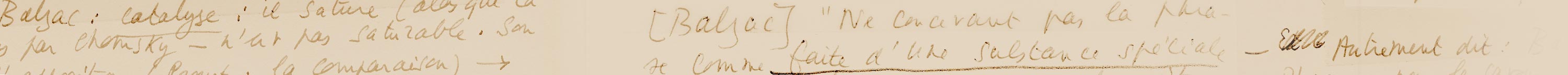







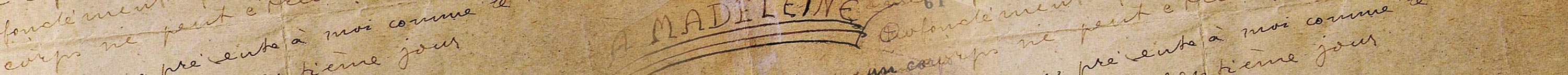

Sommaire
- 1. Introduction
- 1.1. La génétique des textes
- 1.2. Etude systématique du travail de l’écrivain
- 2. Signification de quelques termes techniques
- 2.1. Versions
- 2.2. État
- 3. Fondements algorithmiques
- 3.1. Détection des blocs communs maximaux disjoints
- 3.2. Identification des déplacements et des pivots
- 3.3. Calcul des insertions, des suppressions et des remplacements
- 4. Interface de visualisation
- 4.1. Partie supérieure : les textes
- 4.2. Partie inférieure : information d’usage
- 4.4.1. Transformations
- 4.4.2. Légende
- 4.4.3. Paramètres
- 4.4.4. Commentaires
- 4.5. Comparaison entre "comparaisons de versions"
- 5. Interprétation génétique
- 5. 1. Analyse d’un passage : Andrée Chedid
- 5.2.Analyse d’un dossier complet. Point de vue global sur la genèse d’un texte : une nouvelle de Pascal Quignard, Bernon l’enfant.
- 6. Conclusion
- Notes de bas de page
1. Introduction
Dans le cadre d’un projet de recherche intitulé EDITE1 : Etude Diachronique du Travail de l’Écrivain, visant à procéder à un relevé systématique des transformations à l’œuvre dans le processus d’écriture, nous avons élaboré un logiciel, MEDITE, prototype informatique identifiant les transformations entre une version et l’autre d’un même texte. Cet article rend compte de ce projet et de son avancée.
1.1. La génétique des textes
La génétique des textes2 repose sur l’hypothèse et l’observation que toute œuvre s’inscrit dans le temps. Sa pratique consiste à conduire parallèlement deux séries d’observations :
- celle liée au dépliement des différentes strates d’écriture, grâce à l’élucidation des traces graphiques laissées par l’écrivain sur le manuscrit
- celle liée à la découverte des différentes étapes d’écriture, c’est-à-dire de l’ordre chronologique des gestes de scription et d’élaboration du texte.
Dépliement du manuscrit sur ses différents états et ordonnancement temporel de l’écriture du texte sont ainsi les deux versants indissociablement liés de la critique génétique. L’interprétation qui consiste à présenter la genèse de l’œuvre comme processus rythmé – chaque fois de façon singulière – d’élaboration du texte "final", en dépend.
1.2. Etude systématique du travail de l’écrivain
Le travail d’ajustage auquel se livre l’écrivain dans ses repentirs successifs, ses coupes ou ses insertions, fait ici l’objet d’une étude systématique à l’aide d’outils informatiques qui s’inspirent partiellement de ceux développés pour l’étude des macromolécules biologiques. Nous avons réalisé un programme qui repère automatiquement les opérations structurales, linguistiques et énonciatives, faisant passer d’un texte à un autre. Ces transformations élémentaires (déplacements, insertions, suppressions et remplacements de blocs de caractères), identifiées depuis longtemps par les spécialistes de la génétique textuelle (Grésillon et Lebrave, 1983, Grésillon, 1994, Hay, 2002, etc.), peuvent ensuite être associées aux catégories syntaxiques ou sémantiques des mots ou des groupes de mots pour donner naissance à des opérations linguistiques de réécriture (déplacement d’un adverbe, remplacement d’un mot par un hyperonyme ou par un hyponyme, suppression ou ajout d’un adjectif etc.) (Fenoglio et Boucheron, 2002, Fenoglio, 2003 a). Le logiciel que nous avons conçu, MEDITE, mime les opérations exécutées à la main par le philologue qui compare des textes. Autrement dit, il reconstitue automatiquement la séquence temporelle des corrections, adjonctions et ratures opérées par l’auteur sur son manuscrit à partir de la comparaison de deux états de ce même manuscrit. Ce logiciel comprend une interface permettant aussi bien de visualiser les modifications faisant passer d’un état du texte à un autre, que de recenser toutes les modifications, ajouts, suppressions, déplacements ou remplacements. L’automatisation autorise à la fois une répétition à l’identique de ces opérations, et une systématisation de la démarche sur des textes longs qu’il eut été très pénible de traiter manuellement. On peut ainsi travailler sur des articles, voire sur des livres entiers, et procéder à des études statistiques afin de caractériser le style de réécriture de tel ou tel auteur, et d’identifier, pour un même auteur, les différentes phases et formes de réécriture : expansion, resserrement etc.
De nombreuses applications sont envisagées. Originellement, le projet fut conçu pour la critique génétique : il s’agissait d’aider à comparer des brouillons d’auteurs, afin de saisir la nature du travail de réécriture. Depuis, bien d’autres perspectives s’ouvrent, en particulier, la comparaison de variantes pour la littérature médiévale (Cf « Eloge de la variante » (Cerquiglini, 1989)). Sans compter qu’à partir de la détection des transformations faisant passer d’un état à un autre, il est loisible de construire une distance entre états et, par là, d’engendre l’arbre phylogénétique de tous les états qui rapproche les états les plus proches et, à partir de là, reconstitue la filiations des versions d’un manuscrit.
Dans cet article nous nous restreindrons à la présentation du projet d’Etude diachronique et interprétative du Travail de l’Écrivain et de son logiciel MEDITE, à ses fondements algorithmiques et à son interface de visualisation. Plus précisément, l’article se divise en quatre parties : après avoir précisé le sens d’un certain nombre de termes techniques employés par les généticiens du texte, nous aborderons les fondements algorithmiques du programme, puis, dans une troisième nous présenterons l’interface graphique. Enfin, dans une dernière partie, nous montrerons comment une interprétation génétique peut en être tirée proposée à partir de MEDITE.
2. Signification de quelques termes techniques
La génétique textuelle étudie les processus d’écriture des textes à partir des traces laissées sur les brouillons. Généralement, du moins pour la plupart des auteurs d’avant l’âge informatique, des brouillons rassemblent ces traces sous forme soit intégralement manuscrite, soit partiellement manuscrite et partiellement tapée à la machine, soit totalement tapée à la machine.
A titre d’illustration, la figure 1 contient la photographie d’un brouillon d’auteur. En l’occurrence, le début d’une nouvelle d’Andrée Chedid, « La robe noire » parue dans le recueil Les saisons de passage (Flammarion, 1996).

Figure 1 : une page d’un manuscrit de « La robe noire » d’Andrée Chedid3 (Fonds Chedid de l’IMEC)
2.1. Versions
Dans la suite, nous distinguerons les différents supports matériels, autrement dit, les brouillons successifs, comme autant de versions de l’œuvre. Ainsi, dans le dossier génétique qui nous intéresse, celui du roman d’Andrée Chedid « La robe noire », l’auteur a recopié cinq fois son texte, donnant naissance à cinq versions. La figure 1 correspond à une de ces versions.
2.2. État
Comme on peut le constater sur la version présentée dans la figure 1, chaque brouillon est annoté, raturé, réécrit, ce qui rend la lecture assez confuse. Toutefois, les chercheurs savent identifier, avec une plus ou moins grande certitude, les différents états du texte, c’est-à-dire les différents textes présents sur une même version. Chacun de ces états correspond à une transcription linéaire qui fait abstraction de l’information visuelle et de la spatialisation : inscriptions marginales, couleurs, notes, etc. tout y est réduit à du texte brut. Sur notre exemple, l’état premier est identifié au texte tapé à la machine et les différentes couleurs du manuscrit sont associées à différentes campagnes de relecture4. Pour faciliter la présentation des choses, nous ne considérerons ici que deux états : le tapuscrit et l’état final (voir figure 2 ci-dessous).

Figure 2 : état initial et état final du texte d’Andrée Chedid dans la version de la figure 1
Bien évidemment, ce n’est là qu’un artifice de présentation. Il appartient dans chaque cas au chercheur de définir les différents états qu’il veut considérer.
Une fois ces états identifiés, le logiciel MEDITE va les comparer de façon à retrouver automatiquement les opérations de réécriture, pour en faire l’inventaire. Ceci étant, il convient de bien noter que la mise en œuvre du logiciel MEDITE présuppose qu’un travail préalable ait dégagé, à partir des différentes versions, les différents états du texte sous forme d’autant de transcriptions linéaires de ce même texte.
3. Fondements algorithmiques
Comme nous venons de le voir, le programme MEDITE prend en entrée deux états d’un même texte de façon à repérer les transformations qui font passer de l’un à l’autre, ou, plus exactement, l’ensemble minimal de transformations qui font passer du texte initial au texte « corrigée ». Formulé de la sorte, le problème apparaît très proche de celui posé par le calcul des « distances d’édition » (Sankoff D and Kruskal J.B., 1983 ; Crochemore M. and Rytter W., 1994) d’où l’acronyme EDITE, qui signifie aussi « Etude Diachronique et Interprétative du Travail de l’Ecrivain ». Rappelons que la notion de « distance d’édition » se fonde sur des opérateurs de transformation, que l’on appelle en termes techniques des « éditions », car ils modifient des chaînes de caractères, et sur la minimisation du coût des transformations qui font passer d’une séquence à une autre.
Or, il s’est rapidement avéré qu’une utilisation des distances d’édition n’était pas possible, du moins telle quelle. En effet, il n’existe de procédure efficace de calcul de la distance d’édition que pour des ensembles d’éditions très restreints, comme l’ensemble dit standard qui comprend les trois opérations de suppression, d’insertion et de remplacement. Dans la mesure où la détection des déplacements joue un rôle important pour la génétique textuelle, et que l’introduction des déplacements dans l’ensemble des éditions change totalement la complexité algorithmique de la procédure de calcul des distances, il est nécessaire de procéder autrement. De plus, la taille des textes (plusieurs centaines de milliers de caractères) interdit l’emploi de procédures d’une complexité polynomiale : il faut se limiter à une complexité linéaire ou, au plus, à une complexité en O(n*lg(n)), n étant la longueur des textes à traiter.
Afin de réduire la complexité et de répondre au mieux au problème posé, nous avons donc conçu un algorithme spécifique s’inspirant des méthodes de programmation dynamique et qui procède en trois étapes :
Détection des blocs communs maximaux disjoints
Identification des déplacements et des pivots
Calcul des insertions, des suppressions et des remplacements
3.1. Détection des blocs communs maximaux disjoints
La détection des blocs maximaux fait appel à des algorithmes classiques (Karp R M, Miller R E and Rosenberg A L, 1972 ; Landraud A, Avril J-F and Chrétienne P, 1989) de recherche d’homologies dans les séquences. Nous n’insisterons donc pas sur la mise en œuvre de ces algorithmes, sauf à dire qu’il y a parfois des recouvrements entre blocs maximaux. Ainsi, les deux chaînes « Il a avalé » et « Il avala » donnent deux blocs maximaux, |Il a | et | aval| qui se recouvrent partiellement. Pour obtenir des blocs maximaux disjoints, il faut introduire une césure. Or, généralement il y a plusieurs possibilités. Sur notre exemple, il y en a trois : |Il a | et | aval|, |Il a | et | aval| ou |Il a | et | aval|, ce qui donne, en soulignant les insertions et les suppressions sur les deux chaînes initiales, les trois solutions suivantes : « Il| a| aval|é » et « Il| aval|a », « Il |a |aval|é » et « Il |aval|a » ou « Il a| a|val|é » et « Il a|val|a ». Dans la mesure du possible, il faut éviter la fragmentation des mots, c’est pourquoi nous avons choisi de mettre en priorité la césure sur les signes de ponctuation ou sur les blancs.
Par ailleurs, toujours pour éviter la fragmentation excessive des mots, nous ne mentionnons que les blocs communs d’une taille supérieure à une valeur seuil fixée arbitrairement. Par défaut ce seuil est de 4, ce qui veut dire qu’avant introduction de la césure, les homologies doivent avoir une longueur supérieure à 4 caractères. De la sorte, nous repérons des mots isolés de longueur supérieure à deux caractères, sachant qu’ils sont entourés de deux frontières de mots (blanc ou signe de ponctuation), ainsi que les préfixes ou les suffixes de plus de trois caractères, ce qui correspond à une syllabe.
Notons que la longueur minimale des blocs est un paramètre qui peut être modifié par l’utilisateur, sans difficulté (Voir section 4.4.3.). Cependant, du fait de l’introduction d’une césure qui supprime les recouvrements, il se peut que des blocs de longueur inférieure à la limite inférieure apparaissent dans les blocs communs. Cela signifie que ces blocs appartiennent à des blocs communs de longueur supérieure à la valeur seuil, mais qu’ils ont été rognés pour éviter des recouvrements.
3.2. Identification des déplacements et des pivots
Parmi l’ensemble des blocs communs maximaux disjoints, certains se retrouvent dans le même ordre dans les deux textes, le texte source et le texte corrigé, tandis que d’autres apparaissent déplacés. Ainsi, si nous avons la séquence de blocs maximaux B1 B2 B3 B4 B5 dans le texte source et la séquence B2 B3 B1 B4 B5 dans le texte corrigé, on peut inférer que le bloc B1 a vraisemblablement été déplacé, même si cette appréciation est subjective, car on pourrait tout autant dire que ce sont les blocs B2 et B3 qui ont été déplacés. L’algorithme que nous avons mis en œuvre détermine les blocs déplacés en essayant de minimiser l’amplitude des déplacements mesurée en nombre de caractères. Plus exactement, cet algorithme prend en considération la taille des blocs maximaux de façon à minimiser le nombre de déplacements de caractères requis pour passer d’une séquence de blocs maximaux à l’autre.
A l’issue de cette phase, on distingue parmi les blocs maximaux disjoints, des blocs dits « déplacés » et des blocs qui apparaissent dans le même ordre dans le texte source et dans le texte cible. Ces derniers sont appelés les « blocs pivots », ou plus simplement les « pivots » de la comparaison.
3.3. Calcul des insertions, des suppressions et des remplacements
Une fois déterminés les « blocs pivots » et les « blocs déplacés », il reste à calculer les suppressions, les insertions et les remplacements. Le programme procède comme suit :
Lorsque deux pivots P et P’ sont jointifs dans le texte source, la chaîne qui sépare P et P’ dans le texte corrigé correspond à une insertion. Notons, pour éviter tout malentendu, que les deux pivots P et P’ ne peuvent être jointifs à la fois dans le texte source et dans le texte corrigé, car sinon, P et P’ ne serait maximaux ni l’un, ni l’autre.
Lorsque deux pivots P et P’ sont jointifs dans le texte corrigé, la chaîne qui sépare P et P’ dans le texte source correspond à une suppression.
Enfin, lorsque deux pivots P et P’ ne sont jointifs ni dans le texte source, ni dans le texte corrigé, on dit qu’il y a remplacement de la chaîne comprise entre P et P’ dans le texte source, par la chaîne comprise entre P et P’ dans le texte corrigé.
A ce stade, il convient de préciser qu’un même bloc peut être à la fois déplacé et se trouver dans une insertion, une suppression ou un remplacement. En effet, dans le cas de déplacements de petits blocs situés à l’intérieur d’une insertion, d’une suppression ou d’un remplacement, il est souvent préférable de considérer que c’est l’ensemble qui est inséré, supprimé ou remplacé, de façon à éviter une fragmentation excessive des textes. Nous avons introduit deux paramètres qui permettent de lisser plus ou moins les résultats et d’inclure les blocs déplacés dans les insertions, les suppressions ou les remplacements.
Dans tous les cas, l’information sur le déplacement n’est pas omise. Elle vient se surajouter à d’autres informations. C’est particulièrement important pour repérer qu’un mot est « libéré » par un auteur afin d’être réemployé plus loin dans le même texte, sans commettre de répétition.
Notre algorithme a été testé sur de nombreux textes d’écrivains. En confrontant les résultats obtenus avec des interprétations philologiques, on constate que l’on retrouve, pratiquement toujours, les déplacements, les insertions, les suppressions et les remplacements déjà identifiés manuellement par les généticiens du texte.
4. Interface de visualisation
Pour faciliter la lecture des résultats, nous avons programmé une interface de visualisation qui comporte trois fenêtres (voir figure 3) : deux fenêtres dans la partie supérieure, l’une destinée au texte source, l’autre au texte corrigé, et une fenêtre dans la partie inférieure dont le contenu peut varier comme nous allons le voir ici.
4.1. Partie supérieure : les textes
Pour faire fonctionner MEDITE, il faut charger d’abord le texte source dans la fenêtre de gauche et le texte corrigé dans la fenêtre de droite, ce qui se fait, dans l’un et l’autre cas, comme dans un éditeur classique, avec des menus déroulant.
Un bouton permet ensuite de lancer la comparaison au moyen de l’algorithme précédemment décrit. Les résultats s’affichent alors en couleur : insertions, suppressions et remplacements sont marqués chacun par une couleur spécifique, que l’on peut faire varier à loisir. De plus, les blocs déplacés sont soulignés, ce qui autorise une superposition des deux indications : déplacements d’un côté, insertions, suppressions ou remplacements de l’autre.
Enfin, comme sur de très longs textes le lecteur est susceptible de se perdre, un compteur indique au-dessus de chacune des deux fenêtres de la partie supérieure, le numéro d’ordre du premier pivot présent dans la fenêtre de visualisation. L’utilisateur a alors tout loisir de faire défiler les textes à l’aide des ascenseurs, pour mettre les pivots de l’un et de l’autre texte en regard. Pour faciliter encore les choses, il est possible, en cliquant sur un pivot, de faire automatiquement défiler le texte homologue, dans l’autre fenêtre, jusqu’à ce que le pivot correspondant soit mis en regard du premier.
4.2. Partie inférieure : information d’usage
Le contenu de la fenêtre inférieure est spécifié au moyen des différents onglets qui apparaissent au bas de l’interface : transformations, commentaires, légende, paramètres.
4.4.1. Transformations
Par défaut, l’onglet « transformations» est activé et la fenêtre contient l’ensemble des transformations qui font passer du texte source au texte corrigé, à savoir l’ensemble des insertions, des suppressions, des remplacements et des déplacements.
4.4.2. Légende
L’onglet « légende » fait apparaître la légende de l’interface, c’est-à-dire la signification des couleurs, par exemple ici, bleu pour les insertions et les suppressions, vert pour les remplacements et souligné pour les déplacements. Au reste, il est loisible, de modifier manuellement les couleurs des insertions, des suppressions et des déplacements, ainsi que le style des déplacements.
4.4.3. Paramètres
Nous avons précédemment mentionné trois paramètres, l’un porte sur la taille minimale des blocs maximaux recensés, les deux autres, sur le lissage au cours du calcul des insertions, des suppressions et des remplacements. Ces trois paramètres sont accessibles dans la fenêtre du bas, à l’aide de l’onglet « paramètre». On se trouve alors en mesure de modifier ces paramètres à volonté.
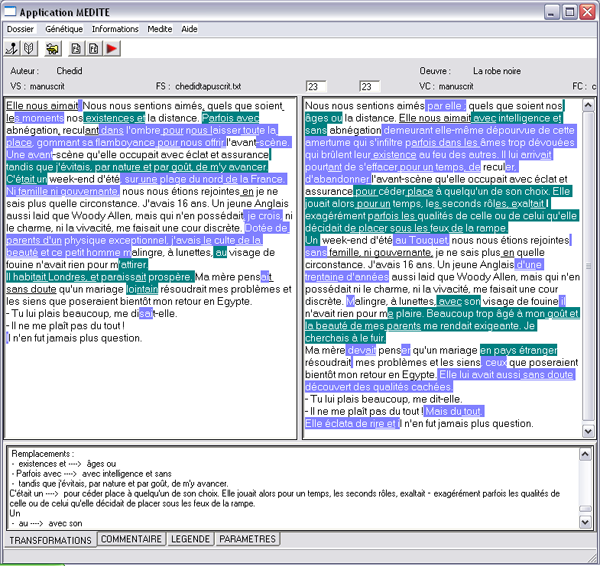
Figure 3 : interface de visualisation de MEDITE
4.4.4. Commentaires
Enfin, l’onglet « commentaires» fait apparaître une fenêtre vide où il est possible d’insérer des notes réutilisables par la suite. De même, on peut coller des parties du texte, ou des transformations, de façon à préparer un article ou une analyse.
Au terme de cette présentation de l’interface de MEDITE, il faut souligner qu’une fois le travail terminé, l’ensemble des textes, des blocs détectés et des commentaires, sont stockés dans un fichier XML dont le contenu peut être exploité par des procédures d’analyse statistique. De plus, ce fichier peut être rechargé automatiquement dans l’interface, ce qui évite d’avoir à exécuter plusieurs fois l’algorithme de comparaison sur de longs textes comme des romans ou des essais philosophiques.
4.5. Comparaison entre "comparaisons de versions"
MEDITE n’est pas le premier logiciel de comparaison de versions, loin de là. Ainsi, les traitements de textes usuels proposent des outils de comparaison de versions très commode lorsque l’on souhaite travailler à plusieurs sur un même document. Cependant, ces comparaisons sont inutilisables pour un philologue qui souhaite analyser finement les variations d’un état à un autre et les transcrire sous forme de séquences d’opérations matérielles sur le texte.
Pour se convaincre de l’insuffisance des techniques de comparaison de versions implantée dans le logiciel Word, reprenons l’exemple donné dans la figure 1. Nous pouvons tous nous reporter à la figure 3 où se trouve effectuée la comparaison avec MEDITE. Examinons maintenant la même comparaison avec Word (voir figure 4).
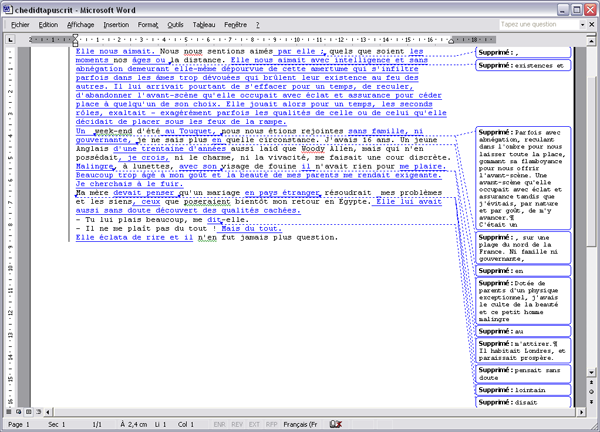
Figure4 : comparaison des deux états du manuscrit d’Andrée Chedid avec Word
Les insuffisances dont souffrent les logiciels usuels de comparaison de versions et qui interdisent de les employer en philologie sont au nombre de quatre :
ils font un certain nombre d’erreurs. Par exemple, dans le cas qui nous intéresse, la première phrase « Elle nous aimait » a été supprimée de l’état initial au cours de la réécriture, or qu’elle est marquée comme étant insérée. Une étude attentive montrerait qu’un nombre important d’erreurs est commis par ces logiciels.
Nous souhaitons prendre en considération tous les opérateurs de transformation identifiés par les généticiens du texte, à savoir l’insertion, la suppression, le remplacement et les déplacements. Or, Word ne considère que l’insertion et la suppression.
L’interface de visualisation est vraiment très mal commode ; il est même quasiment impossible de localiser avec précision les suppressions.
Enfin, on aimerait récupérer l’ensemble de ces transformations pour faire des statistiques et étudier de façon systématique les évolutions sémantiques ou syntaxiques d’une version à l’autre. Or, avec la comparaison des versions de Word, c’est impossible.
5. Interprétation génétique
5. 1. Analyse d’un passage : Andrée Chedid La robe noire
Reportons-nous de nouveau à la copie d’écran donnée dans la figure 3 (p.8). Elle correspond à la comparaison des deux états initiaux et finaux de la version 1 du manuscrit d’Andrée Chedid.
L’application MEDITE permet une visualisation immédiate de tout ce qui se passe entre les états initiaux et finaux de la version 1 du texte. L’exhaustivité des transformations nous est matériellement donnée dans le tableau inférieur. Voilà, immédiatement offert et classé, le matériau minimum nécessaire au généticien du texte.
Ainsi, pour donner une illustration sur ce passage, nous remarquons que les transformations – dont les éléments qui les constituent sont de différentes natures linguistiques - convergent quasiment toutes vers le personnage de la mère « Elle ».
Plus exactement, dans ce passage de l’état initial (EI) à l’état final (EF) s’opère une vraie conversion de point de vue la place de la mère change. Si EI s’efforce de mettre en valeur une générosité maternelle, la suite des suppressions et remplacements montre clairement que EF installe une vision toute différente où la mère s’impose et prend toute la place : le bloc « l’avant-scène qu’elle occupait avec éclat et assurance » reste inchangé alors que les segments contextuels, à droite comme à gauche, passent d’une minimisation à une affirmation amplifiante de cette place (« elle » -> « par elle » ; « Parfois avec abnégation » -> « avec intelligence et sans abnégation » ; « reculant dans l’ombre pour nous laisser toute la place » -> « il lui arrivait pourtant de s’effacer pour un temps » ; insertion de « céder la place à quelqu’un de son choix » etc.)
5.2.Analyse d’un dossier complet. Point de vue global sur la genèse d’un texte : une nouvelle de Pascal Quignard, Bernon l’enfant.
Nous allons considérer un dossier génétique complet constitué de cinq versions d’une même nouvelle, « Bernon l’enfant » de Pascal Quignard – c’est-à-dire des cinq manuscrits successifs de cette nouvelle – qui chacun peut à son tour donner naissance à plusieurs versions. Ainsi, si nous considérons la première version de cette nouvelle (voir figure 5), on peut apercevoir qu’elle est complétée par des annotations et des ratures en rouge et en bleu, le rouge étant vraisemblablement postérieur au bleu, puisqu’il le corrige à certains endroits. Ceci donne cinq états : le tapuscrit, le bleu, les corrections du bleu par le bleu, le rouge, les corrections du rouge par le rouge.
L’analyse par MEDITE des 5 versions de cette nouvelle dans le déploiement de ses différents états (15 états différents au total inégalement répartis selon les versions) fait apparaître 3 grandes campagnes d’écriture à quoi s’ajoute une mise au net (V5).
Comparons, tout d’abord, les deux versions extrêmes de V1 à V5 et repérons tout ce que nous pouvons voir d’emblée :
1) Nous voyons tout de suite que le processus d’écriture est expansif.
2) Allons dans le relevé des transformations. Regardons par exemple la rubrique « remplacements » : nous verrons que plusieurs remplacements visent à ajouter le nom de « Palaiseau », ou que plusieurs remplacements sont motivés par l’ajout de la désignation de « gouverneur ».
Par ailleurs, si nous nous déplaçons à la rubrique « Déplacements », par exemple, nous pouvons immédiatement constater que les remplacements ne sont jamais des segments discursifs mais plutôt des éléments uniques.

Figure 5 : version 1 du manuscrit de Bernon l’enfant (Collection privée)
3) Nous voyons aussi par cette comparaison des deux versions extrêmes où toutes les transformations de la première version à la dernière sont cumulées qu’un des intérêts majeur de la visualisation par MEDITE est de savoir tout de suite ce qui n’a pas changé d’une version à l’autre et là du début à la fin, les blocs inchangés sont immédiatement repérables. Ainsi, La première phrase de l’incipit n’a jamais bougé alors que la dernière phrase a été ajouté tard tandis que les deux phrase précédentes n’ont jamais bougé.
Autre point. En restant dans cette comparaison des deux extrêmes, je peux m’interroger sur une transformation et décider d’aller chercher son moment génétique. Par exemple, je peux me demander à quel moment est fait l’ajout qui va constituer la fin du texte « On monte le crâne au Grenier des Réformés ».
Je vais dans le tableau des insertions des différentes comparaisons et cherche cet ajout. Nous voyons qu’il s’inscrit en deux temps :
- 2rouge bis–>3rouge bis : « on monte le crâne au grenier »
- 3rouge bis–>4 rouge : « auG.. des Réformés. »
On peut ainsi suivre l’évolution d’un passage riche selon toutes les comparaisons possibles
- V1 à V2 : campagne que l’on pourrait qualifier de stylistique : l’auteur joue sur la perfectibilité de l’écriture, le texte est "amélioré" du point de vue des normes linguistiques.
Ainsi les changements suivants : « du visage » -> « de son visage » ; « cette promesse ne tombe pas d’oreille d’un sourd » -> « cette promesse ne tombe pas dans l’oreille d’un sourd »
- V2 à V3 : campagne d’écriture focalisée sur une thématique, celle de la beauté. Stylistiquement se développe une isotopie du beau.
Sur l’écran ci-dessous (voir figure 6), le relevé des insertions fait clairement apparaître une véritable série lexicale autour de ce paradigme sémantique : insertions de « beau », « le bel adolescent », « un bel air s’ajouter à sa beauté »…
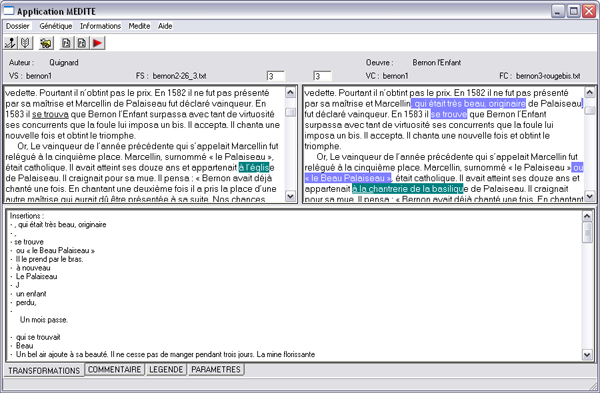
Figure 6 : comparaison de l’état initial de la version 2 et de l’état final de la version 3
Des tournures sont transformées de façon esthétisante : nom de lieu (« à l’église » est remplacée par « à la chantrerie de la basilique », majuscules…
Enfin la visibilité des transformations textuelles par MEDITE fait "entendre" le travail sur les sonorités : « Mon corps n’a pas rejoint mon corps qui a rejoint la mer »
- V3 à V4 : campagne d’écriture thématique, cette fois autour de la passion. L’examen de la liste des transformations montre plusieurs insertions de modalités à caractère affectif et passionnel (« passionnément catholique », « déteste », « hait »)
L’interprétation de ces thèmes fait apparaître une distinction – sinon une opposition – ,filée tout au long du texte, entre « Catholiques » et « Réformés »
Enfin, nous avons découvert, en comparant le dernier état de V1 et le premier de V2 qu’il y avait beaucoup de transformations. On en déduit donc qu’elles ont été faites directement à l’ordinateur : MEDITE fait apparaître immédiatement des transformations non visibles sur le manuscrit. Or, en l’occurrence, cela correspond à la première campagne qui concerne essentiellement des corrections de langue.
En revanche, pour la troisième campagne, celle qui se fourvoie dans la passion, il n’y a pas de corrections directement à l’ordinateur, c’est la plume qui corrige : plus de temps est nécessaire, plus d’allées et venues entre relecture et écriture (3 états).
Ce rapide aperçu, très succinct, donne une idée de la vue d’ensemble que l’on peut rapidement obtenir d’un dossier. Il permet surtout de se rendre compte que des interprétations éminemment qualitatives sont possibles, dès que l’exhaustivité des données génétiques est disponibles ; exhaustivité des données génétiques, cela signifie inventaire et ordonnancement diachronique. Or, MEDITE est spécifiquement conçu de façon à offrir ces données et cet ordre.
Par le biais de MEDITE le généticien dispose d’un matériau exhaustif, immédiatement visible et surtout dont la comparaison, pièce à pièce, est directement accessible et productive.
6. Conclusion
MEDITE est programmé en Python. Il fonctionne actuellement sous les systèmes d’exploitation Windows et LINUX. Une version Mac OS X devrait voir le jour dans les prochains mois. Plusieurs corpus sont actuellement à l’étude avec ce logiciel : Andrée Chedid, La robe noire, Louis Althusser, Freud et Lacan, Marcel Proust, Cahier, Pascal Quignard, Bernon l’enfant. Dès à présent, le logiciel permet d’effectuer automatiquement des études trop fastidieuses pour être réalisées manuellement. Nous devrions donc, grâce au logiciel MEDITE, ouvrir sur une linguistique de l’écrit à même d’aborder quantitativement le travail de réécriture des auteurs. C’est là un premier pas vers de nouvelles applications de l’analyse de données textuelles.
La prise en considération de la dimension temporelle distingue la critique génétique de la philologie qui compare les différentes variantes en relation avec un texte pris comme référence ultime. En quelque sorte, la perspective dynamique et processuelle de la critique génétique s’oppose à l’esthétisme comparatiste de la philologie.
Si le logiciel MEDITE est un outil précieux pour la philologie, il constitue pour la critique génétique un outil nécessaire. En effet, non seulement utile par la rapidité des résultats : MEDITE répertorie automatiquement ce que le chercheur généticien passe un temps incommensurable à relever, installant, d’emblée le travail du généticien dans une "scientificité" plus sûre, il propose un usage qualitatif des données quantitatives et surtout permet au généticien d’infléchir le choix et le rythme des comparaisons aux conditions de l’hypothèse interprétative.
Cette perspective est tout à fait novatrice pour la génétique des textes. En effet, jusque là centrée sur le calibrage qualitatif et plutôt exemplaire, faute de possibilité de relevés exhaustifs des données, faire la genèse d’un texte était se priver soit de l’examen d’un dossier complet si celui-ci était trop long, soit de la vision d’ensemble de la genèse et, de toute façon, de "preuves" fondées sur l’aspect quantitatif.
1 Ce projet répondait à un appel d’offre du programme Société de l’information du CNRS portant sur « Écrit, nouvelles technologies, communication et cognition (2002).
2 La génétique des textes a pris place dans le champ de la critique littéraire dans les années 70. Très exactement c’est en 1968 que l’étude des manuscrits a été reconnue sous la forme de la création d’une équipe CNRS (fondée et dirigée par Louis Hay) chargée de recenser et classer les manuscrits de Heine acquis deux ans plus tôt par la Bibliothèque nationale. L’équipe s’étoffe peu à peu d’autres fonds et après s’être appelée Centre d’histoire et d’Analyse des Manuscrits Modernes (CAM), elle devient, en 1982, un laboratoire : l’Institut des Textes et Manuscrits Modernes (ITEM).
3 Nous reproduisons ce manuscrit avec l’aimable autorisation de l’IMEC.
4 Voir Fenoglio, 2003 b.